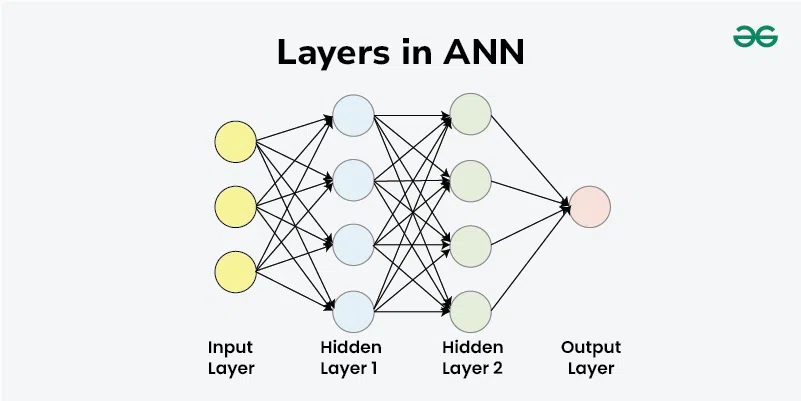
Machine learning, with its ever-expanding applications in various domains, has revolutionized the way we approach complex problems and make data-driven decisions. At the heart of this transformative technology lies neural networks, computational models inspired by the human brain's architecture. Neural networks have the remarkable ability to learn from data and uncover intricate patterns, making them invaluable tools in fields as diverse as image recognition, natural language processing, and autonomous vehicles. To grasp the inner workings of neural networks, we must delve into two essential components: weights and biases.
Table of Content
Weights and Biases in Neural Networks: Unraveling the Core of Machine Learning
In this comprehensive exploration, we will demystify the roles of weights and biases within neural networks, shedding light on how these parameters enable machines to process information, adapt, and make predictions. We will delve into the significance of weights as the strength of connections between neurons, and biases as essential offsets that introduce flexibility into the learning process. As we unravel the mechanics of these components, we will also uncover the iterative learning process of neural networks, involving both forward and backward propagation. To put this into context, we will provide practical examples that illustrate the real-world applications and implications of weights and biases in machine learning.
I. The Foundation of Neural Networks: Weights
Imagine a neural network as a complex web of interconnected nodes, each representing a computational unit known as a neuron. These neurons work together to process information and produce output. However, not all connections between neurons are created equal. This is where weights come into play.
Weights are numerical values associated with the connections between neurons. They determine the strength of these connections and, in turn, the influence that one neuron's output has on another neuron's input. Think of weights as the coefficients that adjust the impact of incoming data. They can increase or decrease the importance of specific information.
During the training phase of a neural network, these weights are adjusted iteratively to minimize the difference between the network's predictions and the actual outcomes. This process is akin to fine-tuning the network's ability to make accurate predictions.
Let's consider a practical example to illustrate the role of weights. Suppose you're building a neural network to recognize handwritten digits. Each pixel in an image of a digit can be considered an input to the network. The weights associated with each pixel determine how much importance the network places on that pixel when making a decision about which digit is represented in the image.
As the network learns from a dataset of labeled digits, it adjusts these weights to give more significance to pixels that are highly correlated with the correct digit and less significance to pixels that are less relevant. Over time, the network learns to recognize patterns in the data and make accurate predictions.
In essence, weights are the neural network's way of learning from data. They capture the relationships between input features and the target output, allowing the network to generalize and make predictions on new, unseen data.
II. Biases: Introducing Flexibility and Adaptability
While weights determine the strength of connections between neurons, biases provide a critical additional layer of flexibility to neural networks. Biases are essentially constants associated with each neuron. Unlike weights, biases are not connected to specific inputs but are added to the neuron's output.
Biases serve as a form of offset or threshold, allowing neurons to activate even when the weighted sum of their inputs is not sufficient on its own. They introduce a level of adaptability that ensures the network can learn and make predictions effectively.
To understand the role of biases, consider a simple example. Imagine a neuron that processes the brightness of an image pixel. Without a bias, this neuron might only activate when the pixel's brightness is exactly at a certain threshold. However, by introducing a bias, you allow the neuron to activate even when the brightness is slightly below or above the threshold.
This flexibility is crucial because real-world data is rarely perfectly aligned with specific thresholds. Biases enable neurons to activate in response to various input conditions, making neural networks more robust and capable of handling complex patterns.
During training, biases are also adjusted to optimize the network's performance. They can be thought of as fine-tuning parameters that help the network fit the data better.
What Does It Mean for a Neuron to Activate?
A neuron in a neural network takes in numbers (inputs), processes them, and decides whether to pass a signal forward. This decision is made using an activation function, which determines how strong the output should be.
Example with a Light Switch
Think of a neuron like a light switch:
- If the total input (after applying weights and adding bias) is high enough, the neuron activates (turns on), passing information forward—like turning the light on.
- If the total input is too low, the neuron stays off, meaning it doesn’t send any signal—like keeping the light off.
Activation in Math Terms
A neuron calculates:
output=activation function(∑(weights×inputs)+bias)\text{output} = \text{activation function}(\sum (\text{weights} \times \text{inputs}) + \text{bias})
output=activation function(∑(weights×inputs)+bias)
- If the result is big enough, the neuron activates (produces a strong signal).
- If the result is too small, the neuron might not activate at all (producing little or no signal).
For example, a ReLU activation function works like this:
ReLU(x)=max(0,x)\text{ReLU}(x) = \max(0, x)
ReLU(x)=max(0,x)
- If x=5x = 5
- x=5, the neuron outputs 5 (activated).
- If x=−3x = -3
- x=−3, the neuron outputs 0 (not activated).
Why Does Activation Matter?
- Activated neurons pass information forward, helping the network make decisions.
- Inactive neurons don’t contribute, keeping unnecessary signals from interfering.
- Bias helps adjust when neurons activate, making learning more flexible.
the role of bias in the input layer! In most cases, bias is not necessary in the input layer because the input neurons don’t perform any transformations—they simply pass raw data to the next layer.
Why Bias is Usually Not Used in the Input Layer
- Input neurons don’t compute anything
- The input layer just takes data (like images, numbers, or text) and passes it to the next layer. It doesn't apply weights, so there’s no need for bias to adjust anything.
- Bias is useful when applying weights and activation functions
- Bias is added in layers where neurons calculate weighted sums and pass them through an activation function. Since input neurons don’t do this, they don’t need bias.
- Bias shifts decision boundaries, which isn’t needed for raw inputs
- In hidden layers, bias helps shift activation functions so that neurons activate even when inputs are small. But the input layer doesn’t decide anything—it just forwards data.
When Might Bias Be Used in the Input Layer?
In rare cases, bias might be added if preprocessing isn't done properly, but normally, it’s unnecessary.
Conclusion
Bias is important in hidden and output layers but has no real effect in the input layer since input neurons don’t apply transformations.
III. The Learning Process: Forward and Backward Propagation
Now that we understand the roles of weights and biases, let's explore how they come into play during the learning process of a neural network.
A. Forward Propagation
Forward propagation is the initial phase of processing input data through the neural network to produce an output or prediction. Here's how it works:
- Input Layer: The input data is fed into the neural network's input layer.
- Weighted Sum: Each neuron in the subsequent layers calculates a weighted sum of the inputs it receives, where the weights are the adjustable parameters.
- Adding Biases: To this weighted sum, the bias associated with each neuron is added. This introduces an offset or threshold for activation.
- Activation Function: The result of the weighted sum plus bias is passed through an activation function. This function determines whether the neuron should activate or remain dormant based on the calculated value.
- Propagation: The output of one layer becomes the input for the next layer, and the process repeats until the final layer produces the network's prediction.
B. Backward Propagation
Once the network has made a prediction, it's essential to evaluate how accurate that prediction is and make adjustments to improve future predictions. This is where backward propagation comes into play:
- Error Calculation: The prediction made by the network is compared to the actual target or ground truth. The resulting error, often quantified as a loss or cost, measures the disparity between prediction and reality.
- Gradient Descent: Backward propagation involves minimizing this error. To do so, the network calculates the gradient of the error with respect to the weights and biases. This gradient points in the direction of the steepest decrease in error.
- Weight and Bias Updates: The network uses this gradient information to update the weights and biases throughout the network. The goal is to find the values that minimize the error.
- Iterative Process: This process of forward and backward propagation is repeated iteratively on batches of training data. With each iteration, the network's weights and biases get closer to values that minimize the error.
In essence, backward propagation fine-tunes the network's parameters, adjusting weights and biases to make the network's predictions more accurate. This iterative learning process continues until the network achieves a satisfactory level of performance on the training data.
IV. Real-World Applications: From Image Recognition to Natural Language Processing
To fully appreciate the significance of weights and biases, let's explore some real-world applications where neural networks shine and where the roles of these parameters become evident.
One of the most prominent applications of neural networks is image recognition. Neural networks have demonstrated remarkable abilities in identifying objects, faces, and even handwriting in images.
Consider a neural network tasked with recognizing cats in photographs. The input to the network consists of pixel values representing the image. Each pixel's importance is determined by the weights associated with it. If certain pixels contain features highly indicative of a cat (such as whiskers, ears, or a tail), the corresponding weights are adjusted to give these pixels more influence over the network's decision.
Additionally, biases play a crucial role in this context. They allow neurons to activate even if the combination of weighted pixel values falls slightly below the threshold required to recognize a cat. Biases introduce the flexibility needed to account for variations in cat images, such as differences in lighting, pose, or background.
Through the training process, the network fine-tunes its weights and biases, learning to recognize cats based on the patterns it discovers in the training dataset. Once trained, the network can accurately classify new, unseen images as either containing a cat or not.
In the realm of natural language processing, neural networks have transformed our ability to understand and generate human language. Applications range from sentiment analysis and language translation to chatbots and voice assistants.
Consider the task of sentiment analysis, where a neural network determines the sentiment (positive, negative, or neutral) of a given text. The input to the network is a sequence of words, each represented as a numerical vector. The importance of each word in influencing the sentiment prediction is determined by the weights associated with these word vectors.
Weights play a critical role in capturing the nuances of language. For instance, in a sentence like "I absolutely loved the movie," the word "loved" should carry more weight in predicting a positive sentiment than the word "absolutely." During training, the network learns these weightings by analyzing a dataset of labeled text examples.
Biases, on the other hand, allow the network to adapt to different writing styles and contexts. They ensure that the network can activate even if the weighted sum of word vectors falls slightly below the threshold for a particular sentiment category.
Through iterative learning, the network refines its weights and biases to become proficient at sentiment analysis. It can then analyze and classify the sentiment of new, unseen text data, enabling applications like automated review analysis and customer feedback processing.
C. Autonomous Vehicles
Autonomous vehicles represent an exciting frontier where neural networks, along with their weights and biases, are making a significant impact. These vehicles rely on neural networks for tasks such as object detection, path planning, and decision-making.
Consider the task of detecting pedestrians in the vicinity of an autonomous vehicle. The vehicle's sensors, such as cameras and lidar, capture a continuous stream of data. Neural networks process this data, with weights determining the importance of various features in identifying pedestrians. For example, the network might assign higher weights to features like the shape of a person's body or their movement patterns.
Biases in this context allow the network to adapt to different lighting conditions, weather, and variations in pedestrian appearance. They ensure that the network can detect pedestrians even in challenging situations.
Through extensive training on diverse datasets, neural networks in autonomous vehicles learn to make accurate decisions about when to brake, accelerate, or steer to ensure safety. Weights and biases play a crucial role in this decision-making process, enabling the vehicle to navigate complex and dynamic environments.
Weights and Bias in Neural Networks - FAQs
What are weights and biases used for?
Weights and biases serve as the adjustable parameters in neural networks. They play a central role in determining how the network processes and learns from data. Weights control the strength of connections between neurons and capture relationships between input features and target outputs. Biases introduce adaptability and flexibility, allowing neurons to activate in response to various input conditions.
Can weights and biases be overused?
While weights and biases are essential components of neural networks, they must be used judiciously. Overusing weights can lead to complex and overfit models that perform poorly on unseen data. Overfitting occurs when a model learns to fit noise in the training data rather than capturing meaningful patterns. When overfitting occurs, regularization techniques are employed to constrain the weights.
Biases, when used appropriately, enhance a network's adaptability. However, excessive use of biases can potentially lead to overfitting as well. Like weights, biases should be adjusted during training to strike a balance between adaptability and generalization.
What is a neural network?
A neural network is a computational model inspired by the structure and function of the human brain. It consists of layers of interconnected neurons or nodes. Neural networks are used for a wide range of tasks, including pattern recognition, classification, regression, and decision-making. They learn from data through the adjustment of weights and biases, enabling them to make predictions and uncover complex relationships in data.
How are weights and biases adjusted during training?
During training, weights and biases are adjusted through an optimization process, often using a technique called gradient descent. The network calculates the gradient of the error (the difference between its predictions and the true values) with respect to the weights and biases. This gradient points in the direction of the steepest decrease in error. The network then updates the weights and biases in small steps, aiming to minimize the error. This process is repeated iteratively on batches of training data until the network converges to a state where it makes accurate predictions.
What role do weights and biases play in the generalization of neural networks?
Weights and biases are crucial for the generalization of neural networks. Generalization refers to a network's ability to make accurate predictions on new, unseen data. By adjusting weights and biases during training, the network learns to capture meaningful patterns in the training data without fitting noise. This allows the network to generalize its knowledge and make accurate predictions on diverse datasets beyond the training set.
VI. Conclusion: The Power of Weights and Biases in Machine Learning
In the ever-evolving landscape of machine learning, neural networks have emerged as powerful tools for solving complex problems and making sense of vast datasets. At the core of these networks lie two fundamental components: weights and biases. These parameters enable neural networks to adapt, learn, and generalize from data, opening the door to a wide range of applications across domains as diverse as computer vision, natural language processing, and autonomous vehicles.
Weights serve as the levers that control the strength of connections between neurons, allowing the network to prioritize relevant information in the data. Biases introduce flexibility and adaptability, ensuring that neurons can activate in various contexts and conditions. Together, these parameters make neural networks robust learners capable of uncovering intricate patterns in data.
The learning process of neural networks, involving forward and backward propagation, is a testament to the power of iterative refinement. Through this process, networks adjust their weights and biases to minimize errors and make accurate predictions. It is in this iterative journey that neural networks transform from novices to experts, capable of handling real-world challenges.
As we look to the future of machine learning and artificial intelligence, understanding the roles and significance of weights and biases in neural networks will remain essential. These components not only drive the success of current applications but also pave the way for innovative solutions to complex problems that were once deemed insurmountable.
In conclusion, weights and biases are the unsung heroes of the machine learning revolution, quietly shaping the future of technology and enabling machines to understand, adapt, and make informed decisions in an increasingly data-driven world.